Learning to Describe Scenes via Privacy-aware Optical Lens
Learning to Describe Scenes via Privacy-aware Optical Lens
May 1, 2024·





Paula Arguello
Jhon Lopez
Karen Sanchez
Carlos Hinojosa
Hoover Rueda-Chacón
Henry Arguello
Abstract
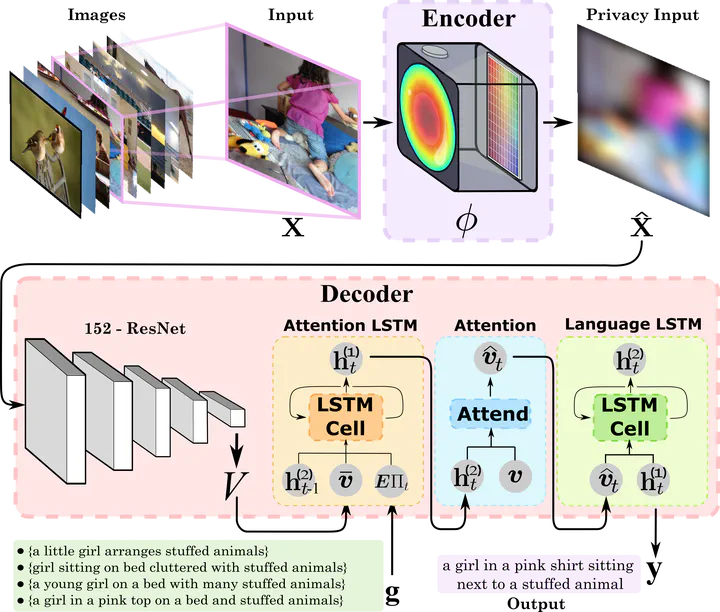
Image caption generation textually summarizes the visual content of an image. This task has gained popularity at the turning point of computer vision (CV) and natural language processing (NLP). Images used to train image captioning models may contain sensitive data that should be confidential, such as faces, personal characteristics, documents, children, etc. This work focuses on protecting privacy in the image captioning task, directly from the image acquisition stage. For this, a refractive lens was designed to ensure privacy using an end-to-end deep learning-based optimization approach. The designed lens blurs sensitive visual attributes in the acquired image while extracting essential features to generate captions even from highly distorted images. The image caption network implements two long short-term memory networks (LSTMs) with an attention module in between to ensure high-quality captions. This method was tested and validated through simulations in the COCO dataset. The results showed a better balance between privacy and usability compared to traditional methods that do not consider privacy.
Type
Publication
LatinX in CV (LXCV) Research at CVPR 2024