Learning to Describe Scenes via Privacy-aware Designed Optical Lens
Learning to Describe Scenes via Privacy-aware Designed Optical Lens
Jul 29, 2024·


 ,
,
Paula Arguello
Jhon Lopez
Karen Sanchez
Carlos Hinojosa
Fernando Rojas-Morales
Henry Arguello
Abstract
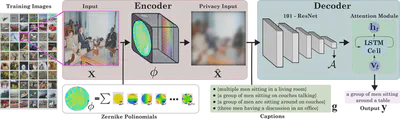
Scene captioning consists of accurately describing the visual information using text, leveraging the capabilities of computer vision and natural language processing. However, current image captioning methods are trained on high-resolution images that may contain private information about individuals within the scene, such as facial attributes or sensitive data. This raises concerns about whether machines require high-resolution images and how we can protect the private information of the users. In this work, we aim to protect privacy in the scene captioning task by addressing the issue directly from the optics before image acquisition. Specifically, motivated by the emerging trend of integrating optics design with algorithms, we introduce a learned refractive lens into the camera to ensure privacy. Our optimized lens obscures sensitive visual attributes, such as faces, ethnicity, gender, and more, in the acquired image while extracting relevant features, enabling descriptions even from highly distorted images. By optimizing the refractive lens and a deep network architecture for image captioning end-to-end, we achieve description generation directly from our distorted images. We validate our approach with extensive simulations and hardware experiments. Our results show that we achieve a better trade-off between privacy and utility when compared to conventional non-privacy-preserving methods on the COCO dataset. For instance, our approach successfully conceals private information within the scene while achieving a BLEU-4 score of 27.0 on the COCO test set.
Type
Publication
IEEE Transactions on Computational Imaging